第 16 章 DOM2 和 DOM3
DOM1(DOM Level 1)主要定义了 HTML 和 XML 文档的底层结构。DOM2(DOM Level 2)和 DOM3(DOM Level 3)在这些结构之上加入更多交互能力,提供了更高级的 XML 特性。实际上,DOM2 和 DOM3 是按照模块化的思路来制定标准的,每个模块之间有一定关联,但分别针对某个 DOM 子集。这些模式如下所示。
❑ DOM Core:在 DOM1 核心部分的基础上,为节点增加方法和属性。
❑ DOM Views:定义基于样式信息的不同视图。
❑ DOM Events:定义通过事件实现 DOM 文档交互。
❑ DOM Style:定义以编程方式访问和修改 CSS 样式的接口。
❑ DOM Traversal and Range:新增遍历 DOM 文档及选择文档内容的接口。
❑ DOM HTML:在 DOM1 HTML 部分的基础上,增加属性、方法和新接口。
❑ DOM Mutation Observers:定义基于 DOM 变化触发回调的接口。这个模块是 DOM4 级模块,用于取代 Mutation Events。
16.1 DOM 的演进
16.1.1 XML 命名空间
XML 命名空间可以实现在一个格式规范的文档中混用不同的 XML 语言,而不必担心元素命名冲突。严格来讲,XML 命名空间在 XHTML 中才支持,HTML 并不支持。因此,本节的示例使用 XHTML。
命名空间是使用 xmlns 指定的。XHTML 的命名空间是"http://www.w3.org/1999/xhtml",应该包含在任何格式规范的XHTML页面的<html>元素中。
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Example XHTML page</title>
</head>
<body>
Hello world!
</body>
</html>对这个例子来说,所有元素都默认属于 XHTML 命名空间。可以使用 xmlns 给命名空间创建一个前缀,格式为“xmlns:前缀”。为避免混淆,属性也可以加上命名空间前缀。
<xhtml:html xmlns:xhtml="http://www.w3.org/1999/xhtml">
<xhtml:head>
<xhtml:title>Example XHTML page</xhtml:title>
</xhtml:head>
<xhtml:body xhtml:class="home">
Hello world!
</xhtml:body>
</xhtml:html>如果文档中只使用一种 XML 语言,那么命名空间前缀其实是多余的,只有一个文档混合使用多种 XML 语言时才有必要。
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Example XHTML page</title>
</head>
<body>
<svg xmlns="http://www.w3.org/2000/svg" version="1.1" viewBox="0 0 100 100" style="width:100%;height:100%">
<rect x="0" y="0" width="100" height="100" style="fill:red" />
</svg>
</body>
</html>1.Node 的变化
在 DOM2 中,Node 类型包含以下特定于命名空间的属性:
❑ localName,不包含命名空间前缀的节点名;
❑ namespaceURI,节点的命名空间 URL,如果未指定则为 null;
❑ prefix,命名空间前缀,如果未指定则为 null。
在节点使用命名空间前缀的情况下,nodeName 等于 prefix + ":" + localName。
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Example XHTML page</title>
</head>
<body>
<s:svg xmlns:s="http://www.w3.org/2000/svg" version="1.1" viewBox="0 0 100 100" style="width:100%;height:100%">
<s:rect x="0" y="0" width="100" height="100" style="fill:red" />
</s:svg>
</body>
</html>DOM3 进一步增加了如下与命名空间相关的方法:
❑ isDefaultNamespace(namespaceURI),返回布尔值,表示 namespaceURI 是否为节点的默认命名空间;
❑ lookupNamespaceURI(prefix),返回给定 prefix 的命名空间 URI;
❑ lookupPrefix(namespaceURI),返回给定 namespaceURI 的前缀。
console.log(document.body.isDefaultNamespace('http://www.w3.org/1999/xhtml')) // true
// 假设svg包含对<s:svg>元素的引用
console.log(svg.lookupPrefix('http://www.w3.org/2000/svg')) // "s"
console.log(svg.lookupNamespaceURI('s')) // "http://www.w3.org/2000/svg"2.Document 的变化
DOM2 在 Document 类型上新增了如下命名空间特定的方法:
❑ createElementNS(namespaceURI, tagName),以给定的标签名 tagName 创建指定命名空间 namespaceURI 的一个新元素;
❑ createAttributeNS(namespaceURI, attributeName),以给定的属性名 attributeName 创建指定命名空间 namespaceURI 的一个新属性;
❑ getElementsByTagNameNS(namespaceURI, tagName),返回指定命名空间 namespaceURI 中所有标签名为 tagName 的元素的 NodeList。
// 创建一个新SVG元素
let svg = document.createElementNS('http://www.w3.org/2000/svg', 'svg')
// 创建一个任意命名空间的新属性
let att = document.createAttributeNS('http://www.somewhere.com', 'random')
// 获取所有XHTML元素
let elems = document.getElementsByTagNameNS('http://www.w3.org/1999/xhtml', '*')3.Element 的变化
DOM2 Core 对 Element 类型的更新主要集中在对属性的操作上。下面是新增的方法:
❑ getAttributeNS(namespaceURI, localName),取得指定命名空间 namespaceURI 中名为 localName 的属性;
❑ getAttributeNodeNS(namespaceURI, localName),取得指定命名空间 namespaceURI 中名为 localName 的属性节点;
❑ getElementsByTagNameNS(namespaceURI, tagName),取得指定命名空间 namespaceURI 中标签名为 tagName 的元素的 NodeList;
❑ hasAttributeNS(namespaceURI, localName),返回布尔值,表示元素中是否有命名空间 namespaceURI 下名为 localName 的属性(注意,DOM2 Core 也添加不带命名空间的 hasAttribute()方法);
❑ removeAttributeNS(namespaceURI, localName),删除指定命名空间 namespaceURI 中名为 localName 的属性;
❑ setAttributeNS(namespaceURI, qualifiedName, value),设置指定命名空间 namespaceURI 中名为 qualifiedName 的属性为 value;
❑ setAttributeNodeNS(attNode),为元素设置(添加)包含命名空间信息的属性节点 attNode。
这些方法与 DOM1 中对应的方法行为相同,除 setAttributeNodeNS()之外都只是多了一个命名空间参数。
4.NamedNodeMap 的变化
NamedNodeMap 也增加了以下处理命名空间的方法。因为 NamedNodeMap 主要表示属性,所以这些方法大都适用于属性:
❑ getNamedItemNS(namespaceURI, localName),取得指定命名空间 namespaceURI 中名为 localName 的项;
❑ removeNamedItemNS(namespaceURI, localName),删除指定命名空间 namespaceURI 中名为 localName 的项;
❑ setNamedItemNS(node),为元素设置(添加)包含命名空间信息的节点。
16.1.2 其他变化
1.DocumentType 的变化
DocumentType 新增了 3 个属性:publicId、systemId 和 internalSubset。publicId、systemId 属性表示文档类型声明中有效但无法使用 DOM1 API 访问的数据。
<!DOCTYPE html PUBLIC "-// W3C// DTD HTML 4.01// EN" "http://www.w3.org/TR/html4/strict.dtd">其 publicId 是"-// W3C// DTD HTML 4.01// EN",而 systemId 是"http://www.w3.org/TR/html4/strict.dtd"。支持DOM2的浏览器应该可以运行以下JavaScript代码:
console.log(document.doctype.publicId)
console.log(document.doctype.systemId)internalSubset 用于访问文档类型声明中可能包含的额外定义
<!DOCTYPE html PUBLIC "-// W3C// DTD XHTML 1.0 Strict// EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd" [<! ELEMENT name (#PCDATA)>] >2.Document 的变化
Document 类型的更新中唯一跟命名空间无关的方法是 importNode()。这个方法的目的是从其他文档获取一个节点并导入到新文档,以便将其插入新文档。每个节点都有一个 ownerDocument 属性,表示所属文档。如果调用 appendChild()方法时传入节点的 ownerDocument 不是指向当前文档,则会发生错误。而调用 importNode()导入其他文档的节点会返回一个新节点,这个新节点的 ownerDocument 属性是正确的。
importNode()方法跟 cloneNode()方法类似,同样接收两个参数:要复制的节点和表示是否同时复制子树的布尔值,返回结果是适合在当前文档中使用的新节点。
let newNode = document.importNode(oldNode, true) // 导入节点及所有后代
document.body.appendChild(newNode)DOM2 View 给 Document 类型增加了新属性 defaultView,是一个指向拥有当前文档的窗口(或窗格<frame>)的指针。这个规范中并没有明确视图何时可用,因此这是添加的唯一一个属性。defaultView 属性得到了除 IE8 及更早版本之外所有浏览器的支持。IE8 及更早版本支持等价的 parentWindow 属性,Opera 也支持这个属性。因此要确定拥有文档的窗口,可以使用以下代码:
let parentWindow = document.defaultView || document.parentWindowDOM2 Core 还针对 document.implementation 对象增加了两个新方法:createDocumentType()和 createDocument()。前者用于创建 DocumentType 类型的新节点,接收 3 个参数:文档类型名称、publicId 和 systemId。比如,以下代码可以创建一个新的 HTML 4.01 严格型文档:
let doctype = document.implementation.createDocumentType('html', '-// W3C// DTD HTML 4.01// EN', 'http://www.w3.org/TR/html4/strict.dtd')已有文档的文档类型不可更改,因此 createDocumentType()只在创建新文档时才会用到,而创建新文档要使用 createDocument()方法。createDocument()接收 3 个参数:文档元素的 namespaceURI、文档元素的标签名和文档类型。比如,下列代码可以创建一个空的 XML 文档:
let doc = document.implementation.createDocument('', 'root', null)这个空文档没有命名空间和文档类型,只指定了<root>作为文档元素。要创建一个 XHTML 文档,可以使用以下代码:
let doctype = document.implementation.createDocumentType('html', '-// W3C// DTD XHTML 1.0 Strict// EN', 'http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd')
let doc = document.implementation.createDocument('http://www.w3.org/1999/xhtml', 'html', doctype)DOM2 HTML 模块也为 document.implamentation 对象添加了 createHTMLDocument()方法。使用这个方法可以创建一个完整的 HTML 文档,包含<html>、<head>、<title>和<body>元素。这个方法只接收一个参数,即新创建文档的标题(放到<title>元素中),返回一个新的 HTML 文档。
let htmldoc = document.implementation.createHTMLDocument('New Doc')
console.log(htmldoc.title) // "New Doc"
console.log(typeof htmldoc.body) // "object"3.Node 的变化
DOM3 新增了两个用于比较节点的方法:isSameNode()和 isEqualNode()。这两个方法都接收一个节点参数,如果这个节点与参考节点相同或相等,则返回 true。节点相同,意味着引用同一个对象;节点相等,意味着节点类型相同,拥有相等的属性(nodeName、nodeValue 等),而且 attributes 和 childNodes 也相等(即同样的位置包含相等的值)。
let div1 = document.createElement('div')
div1.setAttribute('class', 'box')
let div2 = document.createElement('div')
div2.setAttribute('class', 'box')
console.log(div1.isSameNode(div1)) // true
console.log(div1.isEqualNode(div2)) // true
console.log(div1.isSameNode(div2)) // falseDOM3 也增加了给 DOM 节点附加额外数据的方法。setUserData()方法接收 3 个参数:键、值、处理函数,用于给节点追加数据。可以像下面这样把数据添加到一个节点:
document.body.setUserData('name', 'Nicholas', function () {})
let value = document.body.getUserData('name')setUserData()的处理函数会在包含数据的节点被复制、删除、重命名或导入其他文档的时候执行,可以在这时候决定如何处理用户数据。处理函数接收 5 个参数:表示操作类型的数值(1 代表复制,2 代表导入,3 代表删除,4 代表重命名)、数据的键、数据的值、源节点和目标节点。删除节点时,源节点为 null;除复制外,目标节点都为 null。
let div = document.createElement('div')
div.setUserData('name', 'Nicholas', function (operation, key, value, src, dest) {
if (operation == 1) {
dest.setUserData(key, value, function () {})
}
})
let newDiv = div.cloneNode(true)
console.log(newDiv.getUserData('name')) // "Nicholas"4.内嵌窗格的变化
DOM2 HTML 给 HTMLIFrameElement(即<iframe>,内嵌窗格)类型新增了一个属性,叫 contentDocument。这个属性包含代表子内嵌窗格中内容的 document 对象的指针。
let iframe = document.getElementById('myIframe')
let iframeDoc = iframe.contentDocumentcontentDocument 属性是 Document 的实例,拥有所有文档属性和方法,因此可以像使用其他 HTML 文档一样使用它。还有一个属性 contentWindow,返回相应窗格的 window 对象,这个对象上有一个 document 属性。所有现代浏览器都支持 contentDocument 和 contentWindow 属性。
注意
跨源访问子内嵌窗格的 document 对象会受到安全限制。如果内嵌窗格中加载了不同域名(或子域名)的页面,或者该页面使用了不同协议,则访问其 document 对象会抛出错误。
16.2 样式
16.2.1 存取元素样式
CSS 属性名使用连字符表示法,在 JavaScript 中这些属性必须转换为驼峰大小写形式 。大多数属性名会这样直接转换过来。但有一个 CSS 属性名不能直接转换,它就是 float。因为 float 是 JavaScript 的保留字,所以不能用作属性名。DOM2 Style 规定它在 style 对象中对应的属性应该是 cssFloat。
let myDiv = document.getElementById('myDiv')
// 设置背景颜色
myDiv.style.backgroundColor = 'red'
// 修改大小
myDiv.style.width = '100px'
myDiv.style.height = '200px'
// 设置边框
myDiv.style.border = '1px solid black'通过 style 属性设置的值也可以通过 style 对象获取。
<div id="myDiv" style="background-color: blue; width: 10px; height: 25px"></div>
<script>
console.log(myDiv.style.backgroundColor) // "blue"
console.log(myDiv.style.width) // "10px"
console.log(myDiv.style.height) // "25px"
</script>1.DOM 样式属性和方法
DOM2 Style 规范也在 style 对象上定义了一些属性和方法。这些属性和方法提供了元素 style 属性的信息并支持修改,列举如下。
❑ cssText,包含 style 属性中的 CSS 代码。
❑ length,应用给元素的 CSS 属性数量。
❑ parentRule,表示 CSS 信息的 CSSRule 对象(下一节会讨论 CSSRule 类型)。
❑ getPropertyCSSValue(propertyName),返回包含 CSS 属性 propertyName 值的 CSSValue 对象(已废弃)。
❑ getPropertyPriority(propertyName),如果 CSS 属性 propertyName 使用了!important 则返回"important",否则返回空字符串。
❑ getPropertyValue(propertyName),返回属性 propertyName 的字符串值。
❑ item(index),返回索引为 index 的 CSS 属性名。
❑ removeProperty(propertyName),从样式中删除 CSS 属性 propertyName。
❑ setProperty(propertyName, value, priority),设置 CSS 属性 propertyName 的值为 value, priority 是"important"或空字符串。
通过 cssText 属性可以存取样式的 CSS 代码。在读模式下,cssText 返回 style 属性 CSS 代码在浏览器内部的表示。在写模式下,给 cssText 赋值会重写整个 style 属性的值,意味着之前通过 style 属性设置的属性都会丢失。
length 属性是跟 item()方法一起配套迭代 CSS 属性用的。
let prop, value, i, len
for (i = 0, len = myDiv.style.length; i < len; i++) {
prop = myDiv.style[i] //或者用myDiv.style.item(i)
value = myDiv.style.getPropertyValue(prop)
console.log(`prop: ${value}`)
value = myDiv.style.getPropertyCSSValue(prop)
console.log(`prop: ${value.cssText}(${value.cssValueType})`)
}getPropertyValue()方法返回 CSS 属性值的字符串表示。如果需要更多信息,则可以通过 getPropertyCSSValue()获取 CSSValue 对象。这个对象有两个属性:cssText 和 cssValueType。前者的值与 getPropertyValue()方法返回的值一样;后者是一个数值常量,表示当前值的类型(0 代表继承的值,1 代表原始值,2 代表列表,3 代表自定义值)。
removeProperty()方法用于从元素样式中删除指定的 CSS 属性。使用这个方法删除属性意味着会应用该属性的默认(从其他样式表层叠继承的)样式。
myDiv.style.removeProperty('border')2.计算样式
style 对象中包含支持 style 属性的元素为这个属性设置的样式信息,但不包含从其他样式表层叠继承的同样影响该元素的样式信息。DOM2 Style 在 document.defaultView 上增加了 getComputedStyle()方法。这个方法接收两个参数:要取得计算样式的元素和伪元素字符串(如":after")。如果不需要查询伪元素,则第二个参数可以传 null。getComputedStyle()方法返回一个 CSSStyleDeclaration 对象(与 style 属性的类型一样),包含元素的计算样式。在所有浏览器中计算样式都是只读的,不能修改 getComputedStyle()方法返回的对象。
<! DOCTYPE html>
<html>
<head>
<title>Computed Styles Example</title>
<style type="text/css">
#myDiv {
background-color: blue;
width: 100px;
height: 200px;
}
</style>
</head>
<body>
<div id="myDiv" style="background-color: red; border: 1px solid black"></div>
<script>
let myDiv = document.getElementById('myDiv')
let computedStyle = document.defaultView.getComputedStyle(myDiv, null)
console.log(computedStyle.backgroundColor) // "red"
console.log(computedStyle.width) // "100px"
console.log(computedStyle.height) // "200px"
console.log(computedStyle.border) // "1px solid black"(在某些浏览器中)
</script>
</body>
</html>16.2.2 操作样式表
CSSStyleSheet 类型表示 CSS 样式表,包括使用<link>元素和通过<style>元素定义的样式表。注意,这两个元素本身分别是 HTMLLinkElement 和 HTMLStyleElement。CSSStyleSheet 类型是一个通用样式表类型,可以表示以任何方式在 HTML 中定义的样式表。另外,元素特定的类型允许修改 HTML 属性,而 CSSStyleSheet 类型的实例则是一个只读对象(只有一个属性例外)。
CSSStyleSheet 类型继承 StyleSheet,后者可用作非 CSS 样式表的基类。以下是 CSSStyleSheet 从 StyleSheet 继承的属性。
❑ disabled,布尔值,表示样式表是否被禁用了(这个属性是可读写的,因此将它设置为 true 会禁用样式表)。
❑ href,如果是使用<link>包含的样式表,则返回样式表的 URL,否则返回 null。
❑ media,样式表支持的媒体类型集合,这个集合有一个 length 属性和一个 item()方法,跟所有 DOM 集合一样。同样跟所有 DOM 集合一样,也可以使用中括号访问集合中特定的项。如果样式表可用于所有媒体,则返回空列表。
❑ ownerNode,指向拥有当前样式表的节点,在 HTML 中要么是<link>元素要么是<style>元素(在 XML 中可以是处理指令)。如果当前样式表是通过@import 被包含在另一个样式表中,则这个属性值为 null。
❑ parentStyleSheet,如果当前样式表是通过@import 被包含在另一个样式表中,则这个属性指向导入它的样式表。
❑ title, ownerNode 的 title 属性。
❑ type,字符串,表示样式表的类型。对 CSS 样式表来说,就是"text/css"。
上述属性里除了 disabled,其他属性都是只读的。除了上面继承的属性,CSSStyleSheet 类型还支持以下属性和方法。
❑ cssRules,当前样式表包含的样式规则的集合。
❑ ownerRule,如果样式表是使用@import 导入的,则指向导入规则;否则为 null。
❑ deleteRule(index),在指定位置删除 cssRules 中的规则。
❑ insertRule(rule, index),在指定位置向 cssRules 中插入规则。
document.styleSheets 表示文档中可用的样式表集合。这个集合的 length 属性保存着文档中样式表的数量,而每个样式表都可以使用中括号或 item()方法获取。
let sheet = null
for (let i = 0, len = document.styleSheets.length; i < len; i++) {
sheet = document.styleSheets[i]
console.log(sheet.href)
}通过<link>或<style>元素也可以直接获取 CSSStyleSheet 对象。DOM 在这两个元素上暴露了 sheet 属性,其中包含对应的 CSSStyleSheet 对象。
1.CSS 规则
CSSRule 类型表示样式表中的一条规则。这个类型也是一个通用基类,很多类型都继承它,但其中最常用的是表示样式信息的 CSSStyleRule(其他 CSS 规则还有@import、@font-face、@page 和@charset 等,不过这些规则很少需要使用脚本来操作)。以下是 CSSStyleRule 对象上可用的属性。
❑ cssText,返回整条规则的文本。这里的文本可能与样式表中实际的文本不一样,因为浏览器内部处理样式表的方式也不一样。Safari 始终会把所有字母都转换为小写。
❑ parentRule,如果这条规则被其他规则(如@media)包含,则指向包含规则,否则就是 null。
❑ parentStyleSheet,包含当前规则的样式表。
❑ selectorText,返回规则的选择符文本。这里的文本可能与样式表中实际的文本不一样,因为浏览器内部处理样式表的方式也不一样。这个属性在 Firefox、Safari、Chrome 和 IE 中是只读的,在 Opera 中是可以修改的。
❑ style,返回 CSSStyleDeclaration 对象,可以设置和获取当前规则中的样式。
❑ type,数值常量,表示规则类型。对于样式规则,它始终为 1。
cssText 属性与 style.cssText 类似,不过并不完全一样。前者包含选择符文本和环绕样式声明的大括号,而后者则只包含样式声明(类似于元素上的 style.cssText)。此外,cssText 是只读的,而 style.cssText 可以被重写。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<style>
div.box {
background-color: blue;
width: 100px;
height: 200px;
}
</style>
</head>
<body>
<script>
let sheet = document.styleSheets[0]
let rules = sheet.cssRules || sheet.rules // 取得规则集合
let rule = rules[0] // 取得第一条规则
console.log(rule.selectorText) // 'div.box'
console.log(rule.style.cssText) // 'background-color: blue; width: 100px; height: 200px;'
console.log(rule.style.backgroundColor) // 'blue'
console.log(rule.style.width) // '100px'
console.log(rule.style.height) // '200px'
rule.style.backgroundColor = 'red'
console.log(rule.style.backgroundColor) // 'red'
</script>
</body>
</html>2.创建规则
DOM 规定,可以使用 insertRule()方法向样式表中添加新规则。这个方法接收两个参数:规则的文本和表示插入位置的索引值。
sheet.insertRule('body { background-color: silver }', 0) // 使用DOM方法3.删除规则
支持从样式表中删除规则的 DOM 方法是 deleteRule(),它接收一个参数:要删除规则的索引。
sheet.deleteRule(0) // 使用DOM方法16.2.3 元素尺寸
1.偏移尺寸
❑ offsetHeight,元素在垂直方向上占用的像素尺寸,包括它的高度、水平滚动条高度(如果可见)和上、下边框的高度。
❑ offsetLeft,元素左边框外侧距离包含元素左边框内侧的像素数。
❑ offsetTop,元素上边框外侧距离包含元素上边框内侧的像素数。
❑ offsetWidth,元素在水平方向上占用的像素尺寸,包括它的宽度、垂直滚动条宽度(如果可见)和左、右边框的宽度。
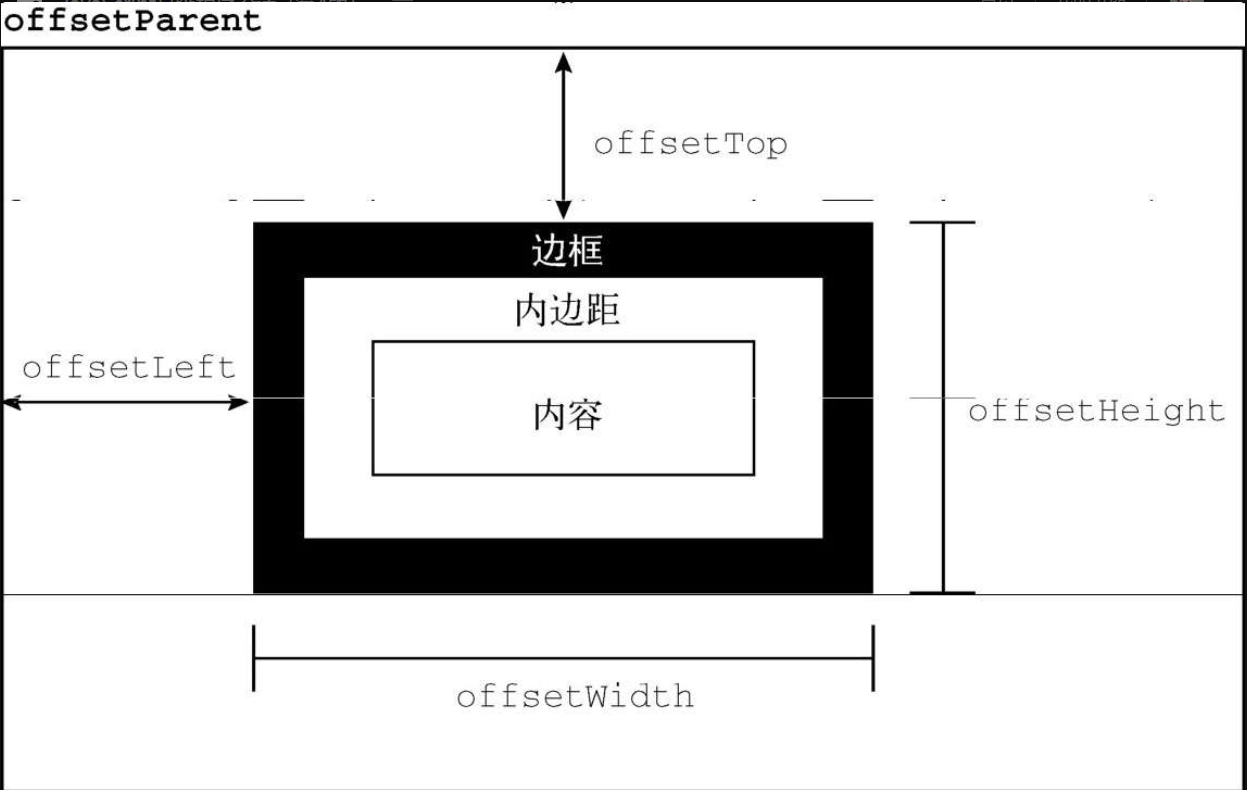
注意
所有这些偏移尺寸属性都是只读的,每次访问都会重新计算。因此,应该尽量减少查询它们的次数。比如把查询的值保存在局量中,就可以避免影响性能。
2.客户端尺寸
clientWidth 是内容区宽度加左、右内边距宽度,clientHeight 是内容区高度加上、下内边距高度。
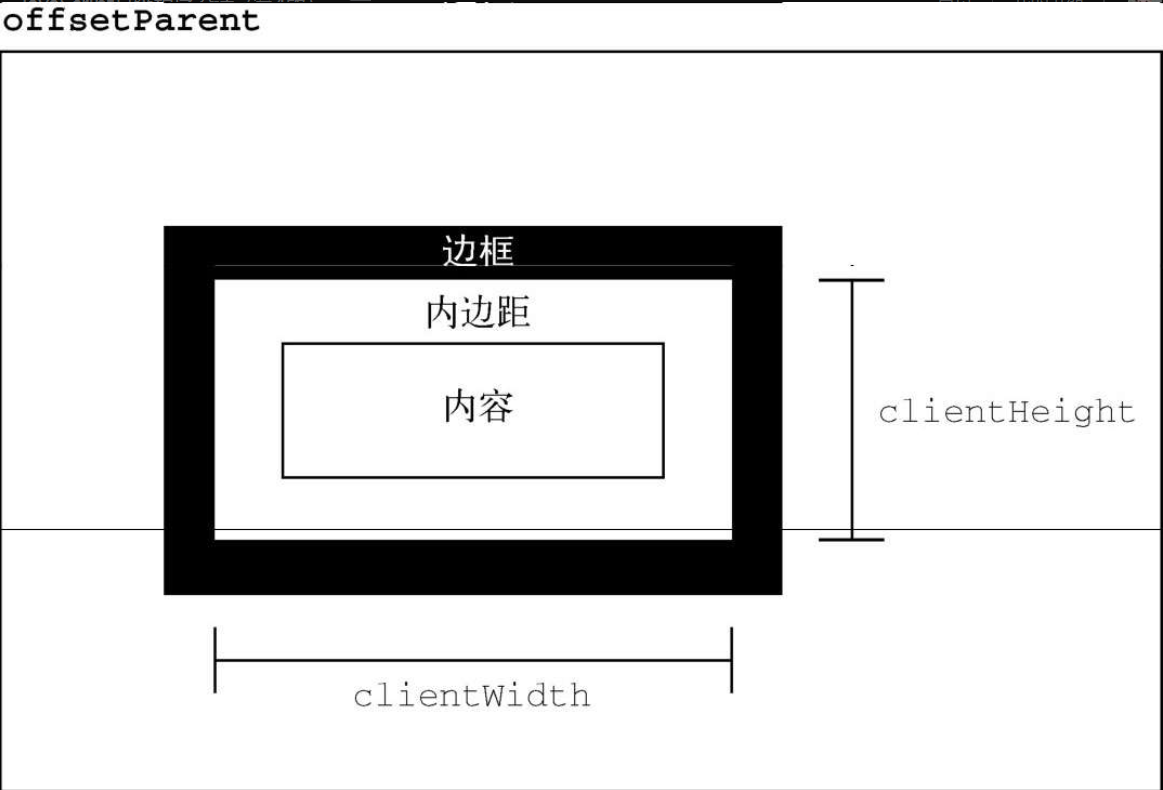
客户端尺寸实际上就是元素内部的空间,因此不包含滚动条占用的空间。这两个属性最常用于确定浏览器视口尺寸,即检测 document.documentElement 的 clientWidth 和 clientHeight。这两个属性表示视口(<html>或<body>元素)的尺寸。
注意
与偏移尺寸一样,客户端尺寸也是只读的,而且每次访问都会重新计算。
3.滚动尺寸
❑ scrollHeight,没有滚动条出现时,元素内容的总高度。
❑ scrollLeft,内容区左侧隐藏的像素数,设置这个属性可以改变元素的滚动位置。
❑ scrollTop,内容区顶部隐藏的像素数,设置这个属性可以改变元素的滚动位置。
❑ scrollWidth,没有滚动条出现时,元素内容的总宽度。
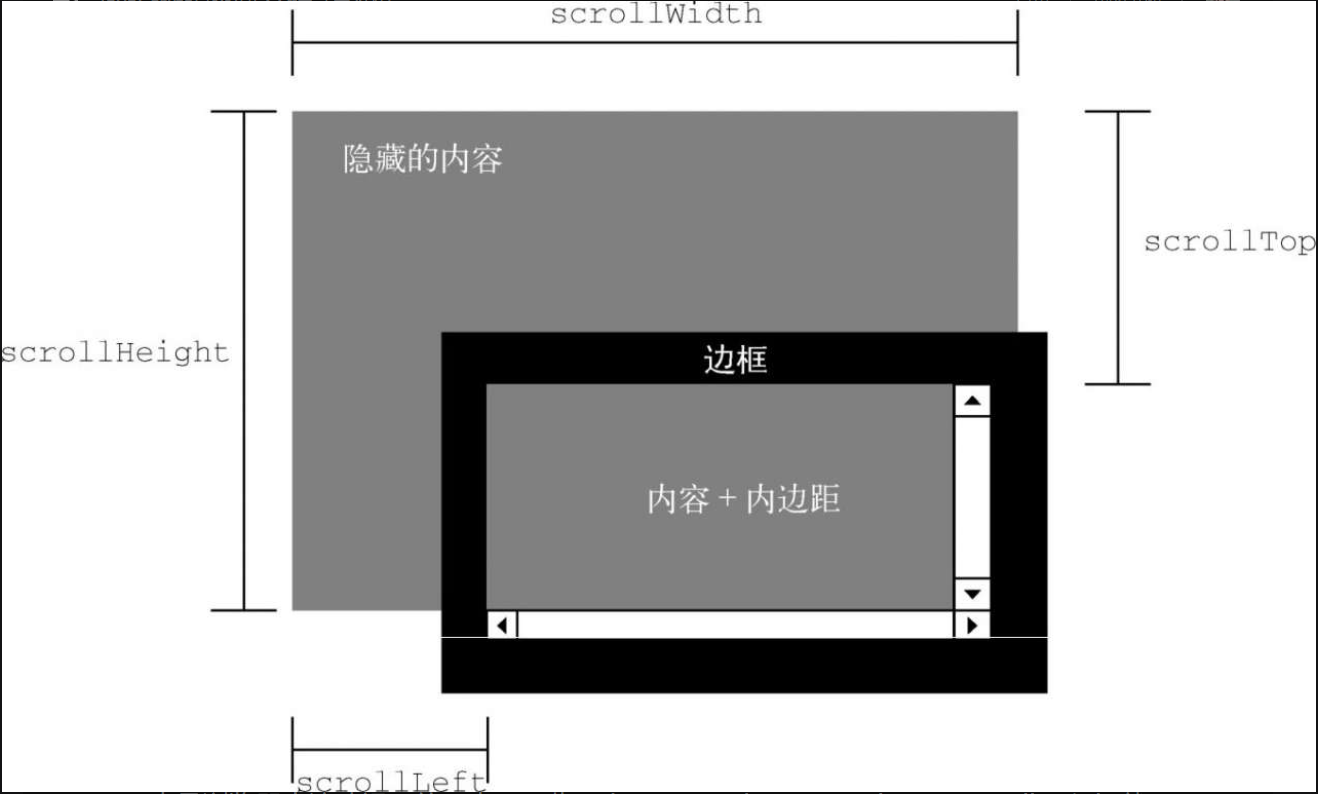
scrollWidth 和 scrollHeight 可以用来确定给定元素内容的实际尺寸。
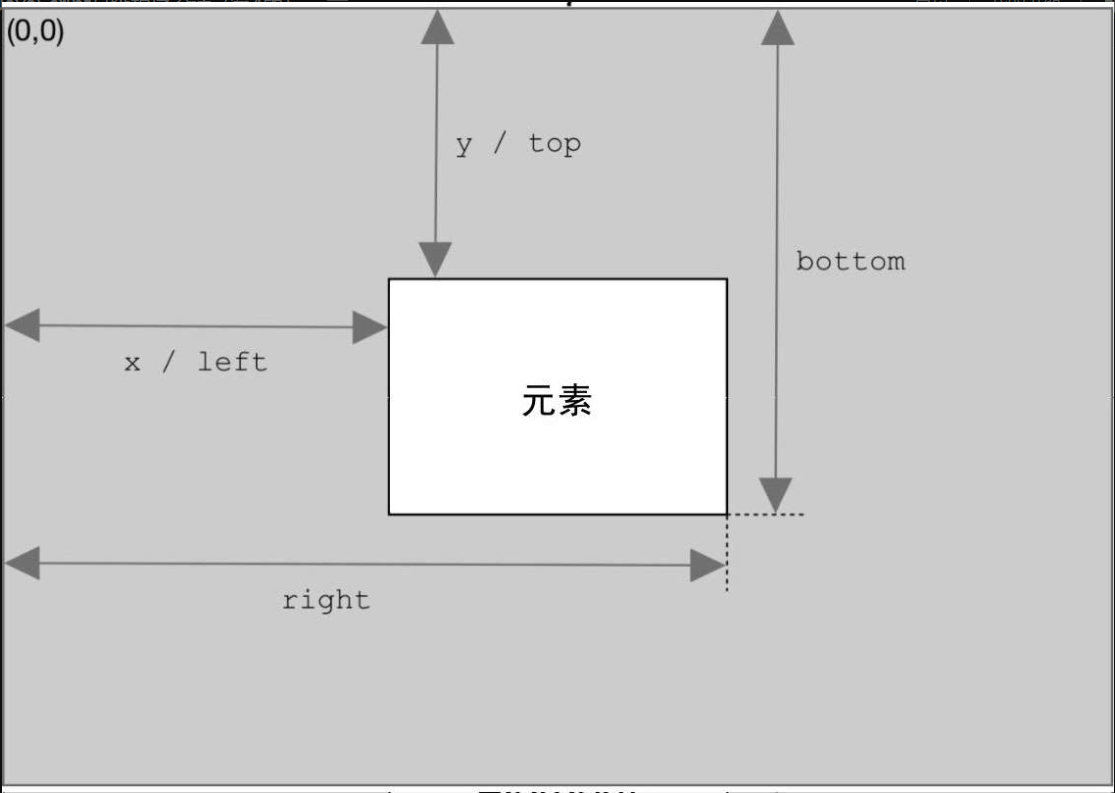
4.确定元素尺寸
浏览器在每个元素上都暴露了 getBoundingClientRect()方法,返回一个 DOMRect 对象,包含 6 个属性:left、top、right、bottom、height 和 width。这些属性给出了元素在页面中相对于视口的位置。
16.3 遍历
DOM2 Traversal and Range 模块定义了两个类型用于辅助顺序遍历 DOM 结构。这两个类型——NodeIterator 和 TreeWalker——从某个起点开始执行对 DOM 结构的深度优先遍历。
16.3.1 NodeIterator
NodeIterator 类型是两个类型中比较简单的,可以通过 document.createNodeIterator()方法创建其实例。这个方法接收以下 4 个参数。
❑ root,作为遍历根节点的节点。
❑ whatToShow,数值代码,表示应该访问哪些节点。
❑ filter, NodeFilter 对象或函数,表示是否接收或跳过特定节点。
❑ entityReferenceExpansion,布尔值,表示是否扩展实体引用。这个参数在 HTML 文档中没有效果,因为实体引用永远不扩展。
whatToShow 参数是一个位掩码,通过应用一个或多个过滤器来指定访问哪些节点。这个参数对应的常量是在 NodeFilter 类型中定义的。
❑ NodeFilter.SHOW_ALL,所有节点。
❑ NodeFilter.SHOW_ELEMENT,元素节点。
❑ NodeFilter.SHOW_ATTRIBUTE,属性节点。由于 DOM 的结构,因此实际上用不上。
❑ NodeFilter.SHOW_TEXT,文本节点。
❑ NodeFilter.SHOW_CDATA_SECTION, CData 区块节点。不是在 HTML 页面中使用的。
❑ NodeFilter.SHOW_ENTITY_REFERENCE,实体引用节点。不是在 HTML 页面中使用的。
❑ NodeFilter.SHOW_ENTITY,实体节点。不是在 HTML 页面中使用的。
❑ NodeFilter.SHOW_PROCESSING_INSTRUCTION,处理指令节点。不是在 HTML 页面中使用的。
❑ NodeFilter.SHOW_COMMENT,注释节点。
❑ NodeFilter.SHOW_DOCUMENT,文档节点。
❑ NodeFilter.SHOW_DOCUMENT_TYPE,文档类型节点。
❑ NodeFilter.SHOW_DOCUMENT_FRAGMENT,文档片段节点。不是在 HTML 页面中使用的。
❑ NodeFilter.SHOW_NOTATION,记号节点。不是在 HTML 页面中使用的。
这些值除了 NodeFilter.SHOW_ALL 之外,都可以组合使用。
let whatToShow = NodeFilter.SHOW_ELEMENT | NodeFilter.SHOW_TEXTfilter 参数可以用来指定自定义 NodeFilter 对象,或者一个作为节点过滤器的函数。NodeFilter 对象只有一个方法 acceptNode(),如果给定节点应该访问就返回 NodeFilter.FILTER_ACCEPT,否则返回 NodeFilter.FILTER_SKIP。因为 NodeFilter 是一个抽象类型,所以不可能创建它的实例。只要创建一个包含 acceptNode()的对象,然后把它传给 createNodeIterator()就可以了。
let filter = {
acceptNode(node) {
return node.tagName.toLowerCase() == 'p' ? NodeFilter.FILTER_ACCEPT : NodeFilter.FILTER_SKIP
}
}
let iterator = document.createNodeIterator(root, NodeFilter.SHOW_ELEMENT, filter, false)
// filter参数还可以是一个函数,与acceptNode()的形式一样,如下面的例子所示:
let filter = function (node) {
return node.tagName.toLowerCase() == 'p' ? NodeFilter.FILTER_ACCEPT : NodeFilter.FILTER_SKIP
}
let iterator = document.createNodeIterator(root, NodeFilter.SHOW_ELEMENT, filter, false)要创建一个简单的遍历所有节点的 NodeIterator,可以使用以下代码:
let iterator = document.createNodeIterator(document, NodeFilter.SHOW_ALL, null, false)NodeIterator 的两个主要方法是 nextNode()和 previousNode()。nextNode()方法在 DOM 子树中以深度优先方式进前一步,而 previousNode()则是在遍历中后退一步。创建 NodeIterator 对象的时候,会有一个内部指针指向根节点,因此第一次调用 nextNode()返回的是根节点。当遍历到达 DOM 树最后一个节点时,nextNode()返回 null。previousNode()方法也是类似的。当遍历到达 DOM 树最后一个节点时,调用 previousNode()返回遍历的根节点后,再次调用也会返回 null。
<div id="div1">
<p><b>Hello</b> world!</p>
<ul>
<li>List item 1</li>
<li>List item 2</li>
<li>List item 3</li>
</ul>
</div>
<script>
let div = document.getElementById('div1')
let iterator = document.createNodeIterator(div, NodeFilter.SHOW_ELEMENT, null, false)
let node = iterator.nextNode()
while (node !== null) {
console.log(node.tagName) // 输出标签名
node = iterator.nextNode()
}
// DIV
// P
// B
// UL
// LI
// LI
// LI
filter = function (node) {
return node.tagName.toLowerCase() == 'li' ? NodeFilter.FILTER_ACCEPT : NodeFilter.FILTER_SKIP
}
iterator = document.createNodeIterator(div, NodeFilter.SHOW_ELEMENT, filter, false)
let node = iterator.nextNode()
while (node !== null) {
console.log(node.tagName) // 输出标签名
node = iterator.nextNode()
}
</script>16.3.2 TreeWalker
TreeWalker 是 NodeIterator 的高级版。除了包含同样的 nextNode()、previousNode()方法,TreeWalker 还添加了如下在 DOM 结构中向不同方向遍历的方法。
❑ parentNode(),遍历到当前节点的父节点。
❑ firstChild(),遍历到当前节点的第一个子节点。
❑ lastChild(),遍历到当前节点的最后一个子节点。
❑ nextSibling(),遍历到当前节点的下一个同胞节点。
❑ previousSibling(),遍历到当前节点的上一个同胞节点。
TreeWalker 对象要调用 document.createTreeWalker()方法来创建,这个方法接收与 document.createNodeIterator()同样的参数:作为遍历起点的根节点、要查看的节点类型、节点过滤器和一个表示是否扩展实体引用的布尔值。因为两者很类似,所以 TreeWalker 通常可以取代 NodeIterator。
let div = document.getElementById('div1')
let filter = function (node) {
return node.tagName.toLowerCase() == 'li' ? NodeFilter.FILTER_ACCEPT : NodeFilter.FILTER_SKIP
}
let walker = document.createTreeWalker(div, NodeFilter.SHOW_ELEMENT, filter, false)
let node = iterator.nextNode()
while (node !== null) {
console.log(node.tagName) // 输出标签名
node = iterator.nextNode()
}不同的是,节点过滤器(filter)除了可以返回 NodeFilter.FILTER_ACCEPT 和 NodeFilter.FILTER_SKIP,还可以返回 NodeFilter.FILTER_REJECT。在使用 TreeWalker 时,NodeFilter.FILTER_SKIP 表示跳过节点,访问子树中的下一个节点,而 NodeFilter.FILTER_REJECT 则表示跳过该节点以及该节点的整个子树。
let div = document.getElementById('div1')
let walker = document.createTreeWalker(div, NodeFilter.SHOW_ELEMENT, null, false)
walker.firstChild() //前往<p>
walker.nextSibling() //前往<ul>
let node = walker.firstChild() //前往第一个<li>
while (node !== null) {
console.log(node.tagName)
node = walker.nextSibling()
}TreeWalker 类型也有一个名为 currentNode 的属性,表示遍历过程中上一次返回的节点(无论使用的是哪个遍历方法)。可以通过修改这个属性来影响接下来遍历的起点。
let node = walker.nextNode()
console.log(node === walker.currentNode) // true
walker.currentNode = document.body // 修改起点16.4 范围
16.4.1 DOM 范围
DOM2 在 Document 类型上定义了一个 createRange()方法,暴露在 document 对象上。使用这个方法可以创建一个 DOM 范围对象。
let range = document.createRange()与节点类似,这个新创建的范围对象是与创建它的文档关联的,不能在其他文档中使用。然后可以使用这个范围在后台选择文档特定的部分。创建范围并指定它的位置之后,可以对范围的内容执行一些操作,从而实现对底层 DOM 树更精细的控制。
每个范围都是 Range 类型的实例,拥有相应的属性和方法。下面的属性提供了与范围在文档中位置相关的信息。
❑ startContainer,范围起点所在的节点(选区中第一个子节点的父节点)。
❑ startOffset,范围起点在 startContainer 中的偏移量。如果 startContainer 是文本节点、注释节点或 CData 区块节点,则 startOffset 指范围起点之前跳过的字符数;否则,表示范围中第一个节点的索引。
❑ endContainer,范围终点所在的节点(选区中最后一个子节点的父节点)。
❑ endOffset,范围起点在 startContainer 中的偏移量(与 startOffset 中偏移量的含义相同)。
❑ commonAncestorContainer,文档中以 startContainer 和 endContainer 为后代的最深的节点。
16.4.2 简单选择
通过范围选择文档中某个部分最简单的方式,就是使用 selectNode()或 selectNodeContents()方法。这两个方法都接收一个节点作为参数,并将该节点的信息添加到调用它的范围。selectNode()方法选择整个节点,包括其后代节点,而 selectNodeContents()只选择节点的后代。
<!DOCTYPE html>
<html>
<body>
<p id="p1"><b>Hello</b> world!</p>
<script>
let range1 = document.createRange(),
range2 = document.createRange(),
p1 = document.getElementById('p1')
range1.selectNode(p1)
// collapsed: false
// commonAncestorContainer: body
// endContainer: body
// endOffset: 2
// startContainer: body
// startOffset: 1
range2.selectNodeContents(p1)
// collapsed: false
// commonAncestorContainer: p#p1
// endContainer: p#p1
// endOffset: 2
// startContainer: p#p1
// startOffset: 0
</script>
</body>
</html>调用 selectNode()时,startContainer、endContainer 和 commonAncestorContainer 都等于传入节点的父节点。在调用 selectNodeContents()时,startContainer、endContainer 和 commonAncestorContainer 属性就是传入的节点。
在像上面这样选定节点或节点后代之后,还可以在范围上调用相应的方法,实现对范围中选区的更精细控制。
❑ setStartBefore(refNode),把范围的起点设置到 refNode 之前,从而让 refNode 成为选区的第一个子节点。startContainer 属性被设置为 refNode.parentNode,而 startOffset 属性被设置为 refNode 在其父节点 childNodes 集合中的索引。
❑ setStartAfter(refNode),把范围的起点设置到 refNode 之后,从而将 refNode 排除在选区之外,让其下一个同胞节点成为选区的第一个子节点。startContainer 属性被设置为 refNode.parentNode, startOffset 属性被设置为 refNode 在其父节点 childNodes 集合中的索引加 1。
❑ setEndBefore(refNode),把范围的终点设置到 refNode 之前,从而将 refNode 排除在选区之外、让其上一个同胞节点成为选区的最后一个子节点。endContainer 属性被设置为 refNode. parentNode, endOffset 属性被设置为 refNode 在其父节点 childNodes 集合中的索引。
❑ setEndAfter(refNode),把范围的终点设置到 refNode 之后,从而让 refNode 成为选区的最后一个子节点。endContainer 属性被设置为 refNode.parentNode, endOffset 属性被设置为 refNode 在其父节点 childNodes 集合中的索引加 1。
16.4.3 复杂选择
要创建复杂的范围,需要使用 setStart()和 setEnd()方法。这两个方法都接收两个参数:参照节点和偏移量。对 setStart()来说,参照节点会成为 startContainer,而偏移量会赋值给 startOffset。对 setEnd()而言,参照节点会成为 endContainer,而偏移量会赋值给 endOffset。
let range1 = document.createRange(),
range2 = document.createRange(),
p1 = document.getElementById('p1'),
p1Index = -1,
i,
len
for (i = 0, len = p1.parentNode.childNodes.length; i < len; i++) {
if (p1.parentNode.childNodes[i] === p1) {
p1Index = i
break
}
}
range1.setStart(p1.parentNode, p1Index)
range1.setEnd(p1.parentNode, p1Index + 1)
range2.setStart(p1, 0)
range2.setEnd(p1, p1.childNodes.length)let p1 = document.getElementById('p1'),
helloNode = p1.firstChild.firstChild,
worldNode = p1.lastChild
let range = document.createRange()
range.setStart(helloNode, 2)
range.setEnd(worldNode, 3)16.4.4 操作范围
创建范围之后,浏览器会在内部创建一个文档片段节点,用于包含范围选区中的节点。为操作范围的内容,选区中的内容必须格式完好。如果范围的起点和终点都在文本节点内部,不是完好的 DOM 结构,则无法在 DOM 中表示。不过,范围能够确定缺失的开始和结束标签,从而可以重构出有效的 DOM 结构,以便后续操作。
第一个方法最容易理解和使用:deleteContents()。顾名思义,这个方法会从文档中删除范围包含的节点。
let p1 = document.getElementById('p1'),
helloNode = p1.firstChild.firstChild,
worldNode = p1.lastChild,
range = document.createRange()
range.setStart(helloNode, 2)
range.setEnd(worldNode, 3)
range.deleteContents()另一个方法 extractContents()跟 deleteContents()类似,也会从文档中移除范围选区。但不同的是,extractContents()方法返回范围对应的文档片段。这样,就可以把范围选中的内容插入文档中其他地方。如果不想把范围从文档中移除,也可以使用 cloneContents()创建一个副本,然后把这个副本插入到文档其他地方。
let p1 = document.getElementById('p1'),
helloNode = p1.firstChild.firstChild,
worldNode = p1.lastChild,
range = document.createRange()
range.setStart(helloNode, 2)
range.setEnd(worldNode, 3)
let fragment = range.extractContents()
p1.parentNode.appendChild(fragment)
fragment = range.cloneContents()
p1.parentNode.appendChild(fragment)16.4.5 范围插入
let p1 = document.getElementById('p1'),
helloNode = p1.firstChild.firstChild,
worldNode = p1.lastChild,
range = document.createRange()
range.setStart(helloNode, 2)
range.setEnd(worldNode, 3)
let span = document.createElement('span')
span.style.color = 'red'
span.appendChild(document.createTextNode('Insertedtext'))
range.insertNode(span)使用 surroundContents()方法插入包含范围的内容。
(1)提取出范围的内容;
(2)在原始文档中范围之前所在的位置插入给定的节点;
(3)将范围对应文档片段的内容添加到给定节点。
这种功能适合在网页中高亮显示某些关键词。
let p1 = document.getElementById('p1'),
helloNode = p1.firstChild.firstChild,
worldNode = p1.lastChild,
range = document.createRange()
range.selectNode(helloNode)
let span = document.createElement('span')
span.style.backgroundColor = 'yellow'
range.surroundContents(span)16.4.6 范围折叠
如果范围并没有选择文档的任何部分,则称为折叠(collapsed)。
折叠范围可以使用 collapse()方法,这个方法接收一个参数:布尔值,表示折叠到范围哪一端。true 表示折叠到起点,false 表示折叠到终点。要确定范围是否已经被折叠,可以检测范围的 collapsed 属性。
range.collapse(true) // 折叠到起点
console.log(range.collapsed) // 输出true测试范围是否被折叠,能够帮助确定范围中的两个节点是否相邻。
<p id="p1">Paragraph 1</p>
<p id="p2">Paragraph 2</p>
<script>
let p1 = document.getElementById('p1'),
p2 = document.getElementById('p2'),
range = document.createRange()
range.setStartAfter(p1)
range.setStartBefore(p2)
console.log(range.collapsed) // true
</script>16.4.7 范围比较
如果有多个范围,则可以使用 compareBoundaryPoints()方法确定范围之间是否存在公共的边界(起点或终点)。这个方法接收两个参数:要比较的范围和一个常量值,表示比较的方式。这个常量参数包括:
❑ Range.START_TO_START(0),比较两个范围的起点;
❑ Range.START_TO_END(1),比较第一个范围的起点和第二个范围的终点;
❑ Range.END_TO_END(2),比较两个范围的终点;
❑ Range.END_TO_START(3),比较第一个范围的终点和第二个范围的起点。
compareBoundaryPoints()方法在第一个范围的边界点位于第二个范围的边界点之前时返回-1,在两个范围的边界点相等时返回 0,在第一个范围的边界点位于第二个范围的边界点之后时返回 1。
let range1 = document.createRange()
let range2 = document.createRange()
let p1 = document.getElementById('p1')
range1.selectNodeContents(p1)
range2.selectNodeContents(p1)
range2.setEndBefore(p1.lastChild)
console.log(range1.compareBoundaryPoints(Range.START_TO_START, range2)) // 0
console.log(range1.compareBoundaryPoints(Range.END_TO_END, range2)) // 116.4.8 复制范围
调用范围的 cloneRange()方法可以复制范围。这个方法会创建调用它的范围的副本:
let newRange = range.cloneRange()新范围包含与原始范围一样的属性,修改其边界点不会影响原始范围。
16.4.9 清理
在使用完范围之后,最好调用 detach()方法把范围从创建它的文档中剥离。调用 detach()之后,就可以放心解除对范围的引用,以便垃圾回收程序释放它所占用的内存。
range.detach() // 从文档中剥离范围
range = null // 解除引用16.5 小结
DOM2 Style 模块定义了如何操作元素的样式信息。
❑ 每个元素都有一个关联的 style 对象,可用于确定和修改元素特定的样式。
❑ 要确定元素的计算样式,包括应用到元素身上的所有 CSS 规则,可以使用 getComputedStyle()方法。
❑ 通过 document.styleSheets 集合可以访问文档上所有的样式表。
DOM2 Traversal and Range 模块定义了与 DOM 结构交互的不同方式。
❑ NodeIterator 和 TreeWalker 可以对 DOM 树执行深度优先的遍历。
❑ NodeIterator 接口很简单,每次只能向前和向后移动一步。TreeWalker 除了支持同样的行为,还支持在 DOM 结构的所有方向移动,包括父节点、同胞节点和子节点。
❑ 范围是选择 DOM 结构中特定部分并进行操作的一种方式。
❑ 通过范围的选区可以在保持文档结构完好的同时从文档中移除内容,也可复制文档中相应的部分。